

Authors:
(1) Qian Yang, Zhejiang University, Equal contribution. This work was conducted during Qian Yang’s internship at Alibaba Group;
(2) Jin Xu, Alibaba Group, Equal contribution;
(3) Wenrui Liu, Zhejiang University;
(4) Yunfei Chu, Alibaba Group;
(5) Xiaohuan Zhou, Alibaba Group;
(6) Yichong Leng, Alibaba Group;
(7) Yuanjun Lv, Alibaba Group;
(8) Zhou Zhao, Alibaba Group and Corresponding to Zhou Zhao ([email protected]);
(9) Yichong Leng, Zhejiang University
(10) Chang Zhou, Alibaba Group and Corresponding to Chang Zhou ([email protected]);
(11) Jingren Zhou, Alibaba Group.
Table of Links
4 Experiments
4.3 Human Evaluation and 4.4 Ablation Study of Positional Bias
A Detailed Results of Foundation Benchmark
A Detailed Results of Foundation Benchmark
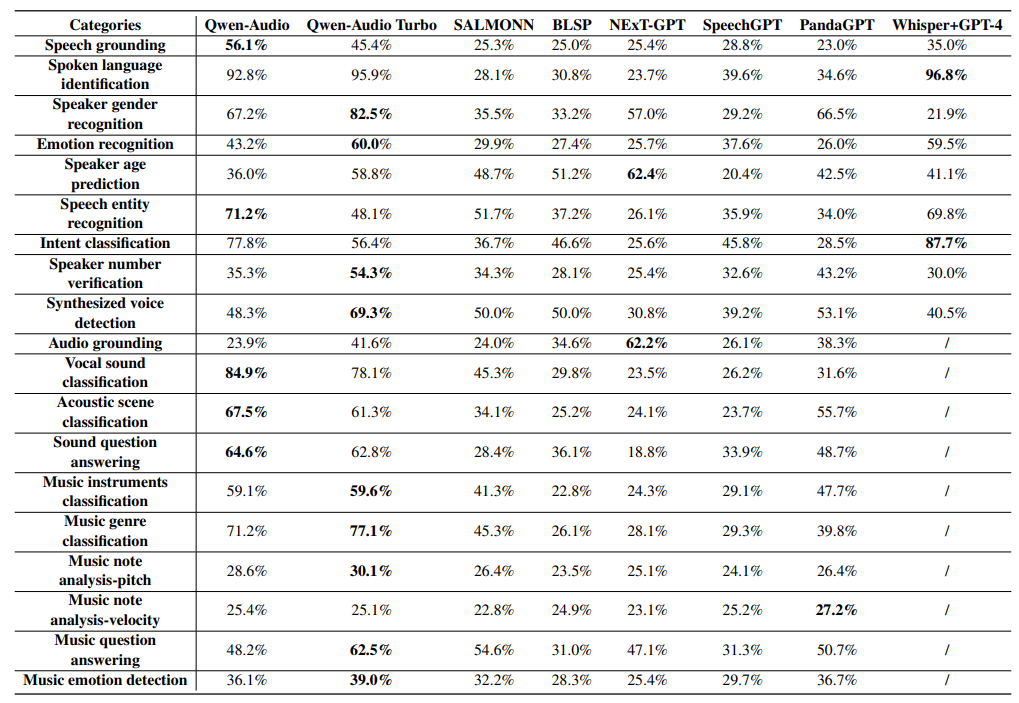
In Table 5, we delineate the performance assessment for each model across the various tasks on the foundation benchmark. With the exception of Speaker Gender Recognition and Synthesized Voice Detection, which are binary-choice tasks, all other tasks necessitate a selection from four options. As such, a random selection in the Speaker Gender Recognition and Synthesized Voice Detection datasets would theoretically achieve an accuracy of 50%, while the expected accuracy for random choices across the remaining datasets stands at 25%. Consequently, any performance metrics that approximate these random baselines are indicative of an absence of discernible proficiency in the respective tasks.
This paper is available on arxiv under CC BY 4.0 DEED license.