

Detailed Results of the Foundation Benchmark
16 Oct 2024
Review the performance of audio-language models in AIR-bench's foundation benchmark, revealing strengths, weaknesses, and insights for future improvements.

AIR-Bench: A New Benchmark for Large Audio-Language Models
16 Oct 2024
This paper introduces AIR-Bench, the first generative evaluation benchmark for LALMs, featuring 19 audio tasks and an evaluation framework for assessing LALMs
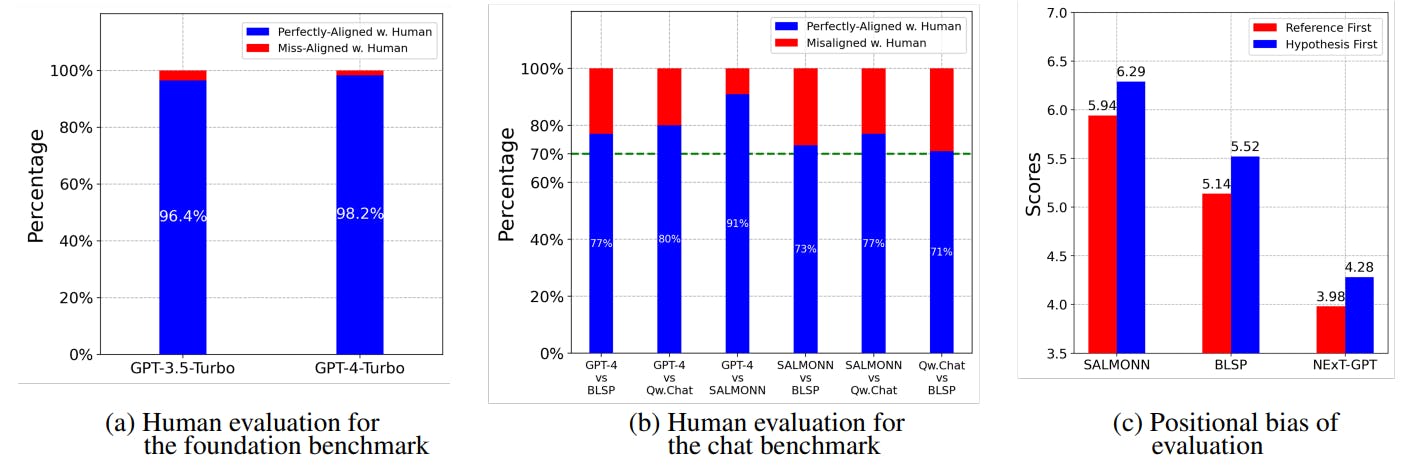
Human Evaluation of Large Audio-Language Models
16 Oct 2024
Explore how GPT-4 aligns with human evaluations in assessing LALMs, revealing insights on performance consistency and the impact of positional bias.

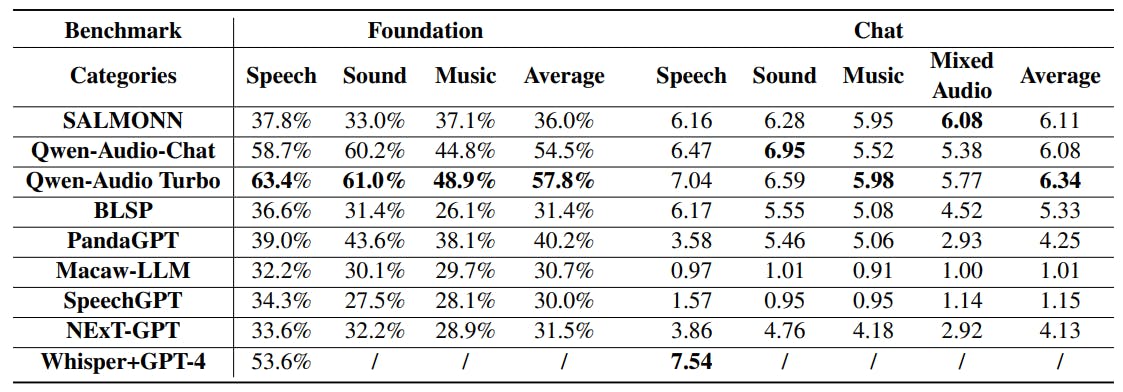
Success Rates and Performance of LALMs
16 Oct 2024
Review LALM evaluation results, highlighting Qwen-Audio Turbo's performance in benchmarks and GPT-4's role in improving success rates across all models.
Performance Assessment of LALMs and Multi-Modality Models
16 Oct 2024
valuating Language-Aligned Audio Models (LALMs) like SpeechGPT and Qwen-AudioChat, using instruction-following benchmarks and latest model checkpoints.
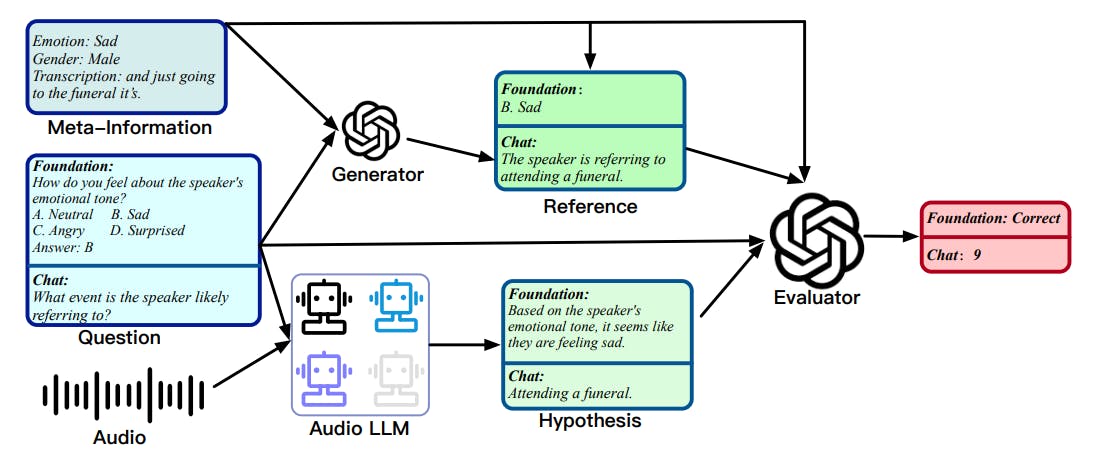
Unified Evaluation Method for LALMs Using GPT-4 in Audio Tasks
16 Oct 2024
This article explores the unified evaluation strategy for Language-Aligned Audio Models (LALMs), focusing on GPT-4's role in assessing audio-based tasks.
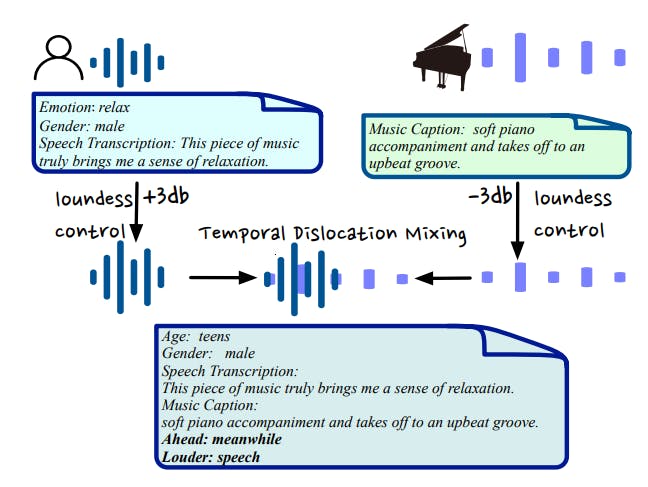
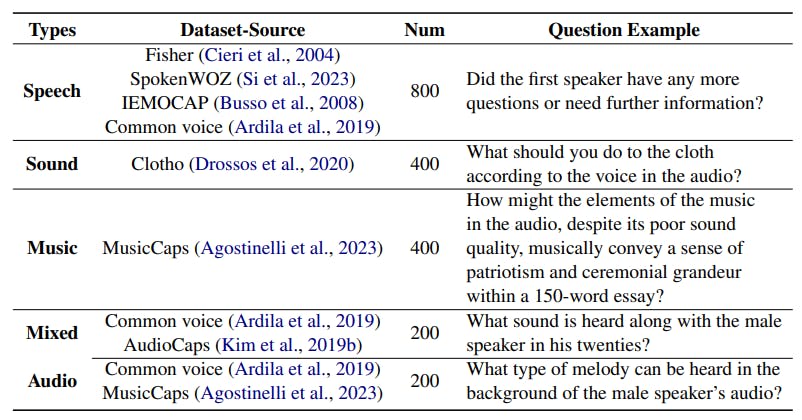
AIR-Bench’s Chat Benchmark: Open-Ended Audio QA with Mixed Audio Complexity
16 Oct 2024
AIR-Bench’s chat benchmark enhances audio complexity through novel mixing strategies and GPT-4-generated open-ended questions.
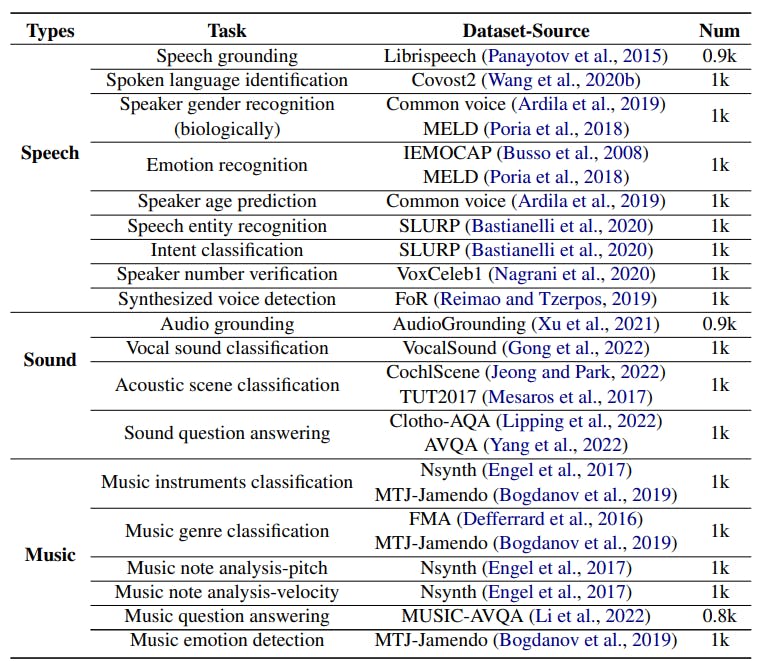
AIR-Bench Foundation: Over 19k Data Samples for Comprehensive Audio Evaluation
16 Oct 2024
AIR-Bench foundation benchmark evaluates 19 audio tasks with 19k+ samples, using GPT-4 to generate single-choice queries and candidate options for diverse tasks
What is AIR-Bench?
16 Oct 2024
AIR-Bench, the first generative benchmark for audio-language models, evaluates audio tasks using a hierarchical approach and GPT-4-based automatic evaluation.