
Authors:
(1) Qian Yang, Zhejiang University, Equal contribution. This work was conducted during Qian Yang’s internship at Alibaba Group;
(2) Jin Xu, Alibaba Group, Equal contribution;
(3) Wenrui Liu, Zhejiang University;
(4) Yunfei Chu, Alibaba Group;
(5) Xiaohuan Zhou, Alibaba Group;
(6) Yichong Leng, Alibaba Group;
(7) Yuanjun Lv, Alibaba Group;
(8) Zhou Zhao, Alibaba Group and Corresponding to Zhou Zhao ([email protected]);
(9) Yichong Leng, Zhejiang University
(10) Chang Zhou, Alibaba Group and Corresponding to Chang Zhou ([email protected]);
(11) Jingren Zhou, Alibaba Group.
Table of Links
4 Experiments
4.3 Human Evaluation and 4.4 Ablation Study of Positional Bias
A Detailed Results of Foundation Benchmark
3.2 Foundation Benchmark
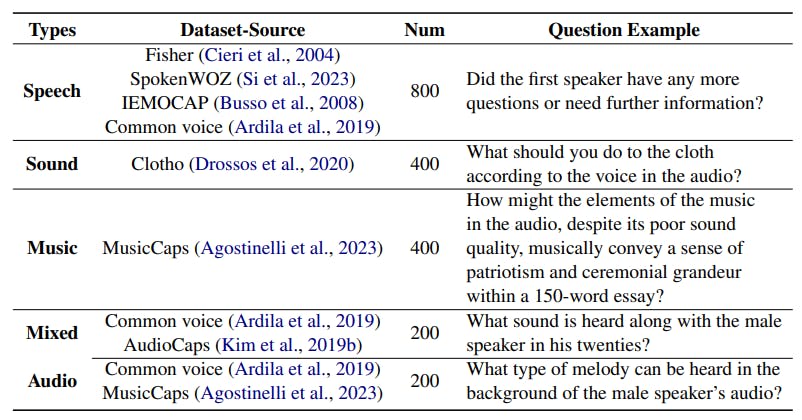
Data Source. We collected over 19k data samples for the foundation dimension, encompassing 19 different subtasks. The data source and statistics
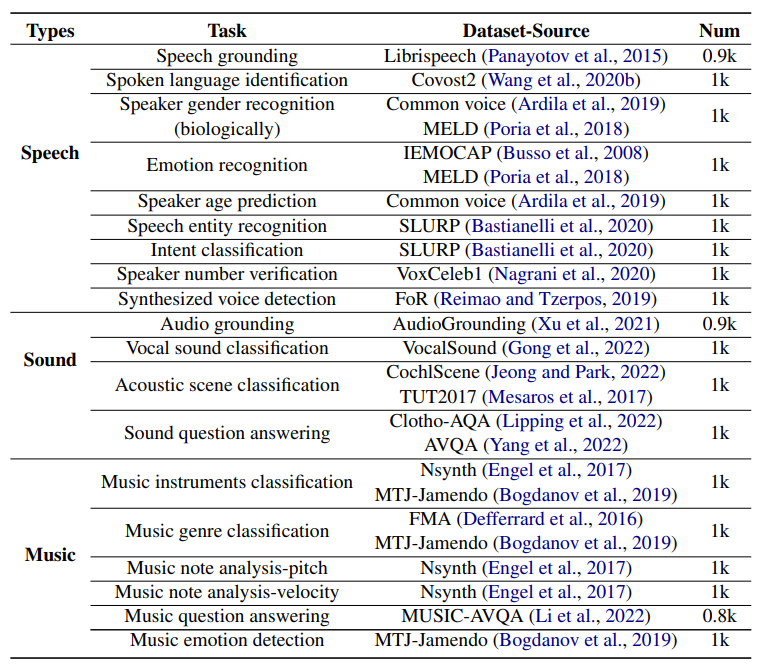
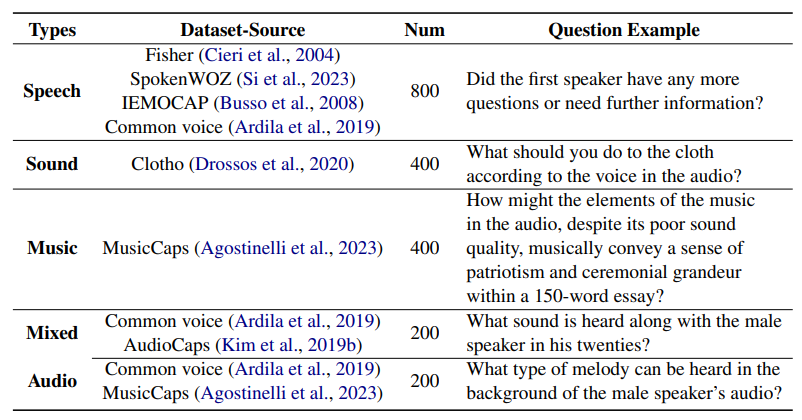
are provided in Table 1. To ensure a fair and comprehensive evaluation of each capability, we aimed for an even distribution of problems related to different abilities during the data collection process. All audio sources were obtained from the original dev or test subsets to prevent data leakage.
Single-choice Query and Reference. The query Q is formed by concatenating a question q and candidate choices C. For the question q, we mainly construct questions through GPT-4 (OpenAI, 2023), except for QA tasks since the datasets inherently contain questions and we can directly re-use them. Specifically, we design the prompt for the distinct task and provide three questions as demonstrations. Subsequently, GPT-4 generates additional diverse questions based on these inputs. The generated questions are manually reviewed, and 50 different questions are selected for each task. The variability in question format aims to evaluate the model’s ability to follow instructions rather than being overly reliant on specific templates. For each question, we further generate candidate choices C from different sources: 1) For tasks with choices in original datasets like AVQA (Yang et al., 2022), we directly re-use it; 2) For classification tasks, we randomly select options from the predetermined set of categories to serve as candidate choices; 3) For other tasks, we prompt GPT-4 to generate candidate choices directly, consisting of one correct option and three incorrect options. We encourage these incorrect options to resemble the correct one, making the single-choice task more challenging. The reference answer is the golden correct choice. To avoid position bias, the candidate choices are randomly shuffled
This paper is available on arxiv under CC BY 4.0 DEED license.