
Authors:
(1) Qian Yang, Zhejiang University, Equal contribution. This work was conducted during Qian Yang’s internship at Alibaba Group;
(2) Jin Xu, Alibaba Group, Equal contribution;
(3) Wenrui Liu, Zhejiang University;
(4) Yunfei Chu, Alibaba Group;
(5) Xiaohuan Zhou, Alibaba Group;
(6) Yichong Leng, Alibaba Group;
(7) Yuanjun Lv, Alibaba Group;
(8) Zhou Zhao, Alibaba Group and Corresponding to Zhou Zhao ([email protected]);
(9) Yichong Leng, Zhejiang University
(10) Chang Zhou, Alibaba Group and Corresponding to Chang Zhou ([email protected]);
(11) Jingren Zhou, Alibaba Group.
Table of Links
4 Experiments
4.3 Human Evaluation and 4.4 Ablation Study of Positional Bias
A Detailed Results of Foundation Benchmark
3.3 Chat Benchmark
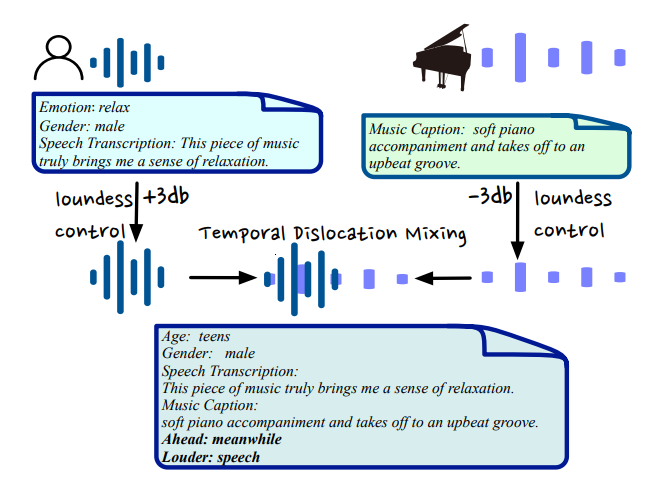
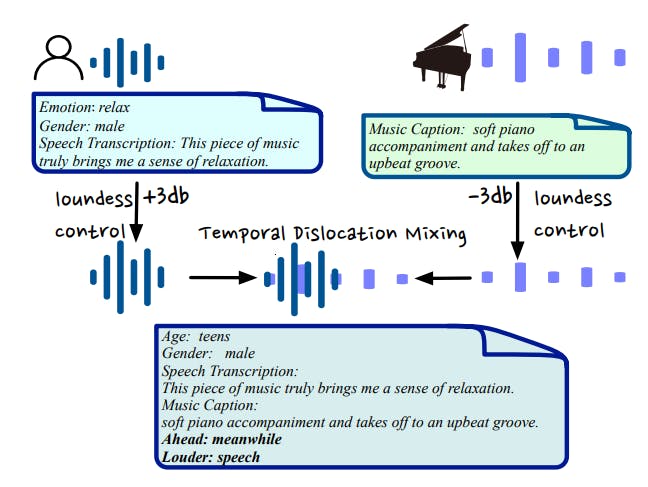
Data Source and Audio Mixing Strategy. As shown in Table 2, we have collected more than 2k data samples spanning various audio types including speech, sound, music, and mixed audio. The purpose of introducing mixed audio is to augment the complexity of the audio signals and make it closer to audio from real-world audio scenarios. To achieve this, we propose a novel mixing strategy involving loudness control and temporal dislocation, as illustrated in Fig. 2. Specifically, we can adjust the relative loudness and temporal relationship between two audio clips for mixing. Then, we can create a complex audio signal that combines their meta-information, such as speech transcription accompanied by a background music caption. Furthermore, the meta-information also includes labels indicating which audio clip is louder and which is ahead in the temporal sequence.
Open-ended Query and Reference. To prompt GPT-4 to generate open-ended question-answer pairs for audio, we should interpret the rich information in each audio with texts. We collect all of meta-information such as gender, age, emotion, transcription, language for speech, caption for natural sound, and instrument, caption for music from the original dataset. Rather than relying on pretrained models to extract this meta-information for each audio clip, we adopt the ground truth metainformation to avoid potential errors.
After gathering meta-information about the audio, we manually construct prompts. These prompts are carefully designed to ensure a comprehensive coverage of chat interactions, taking into consideration the diverse range of audio signals involved. We design the prompts to facilitate the generation of questions related to the perception and reasoning for different types of audio. For the natural sound, the prompts are further tailored to generate questions that involve determining appropriate responses to sound events within a specific scenario. For the music category, prompts are devised to elicit creative writing and story generation questions based on music composition. To ensure the quality of the generated results, these prompts are designed in a manner that enables GPT-4 to automatically filter out responses that are not directly related to audio. Additionally, we manually reviewed all the question-answer pairs to ensure the quality of the questions and the reliability of the answers. The generated answers from GPT-4 are considered as references.
This paper is available on arxiv under CC BY 4.0 DEED license.